
This post delves into a challenging scenario faced by one of the clients I deal with at my current employment.
To provide highlight on what the project does, the client has an application that collects publicly available data for FnB businesses on multiple FnB services, the application would then be able to provide insightful analytics for stores and compare between them in a way that would aid FnB companies in providing better prices and strategies on when and where to open their upcoming branches along with seeing their ranks between other stores
Current architecture
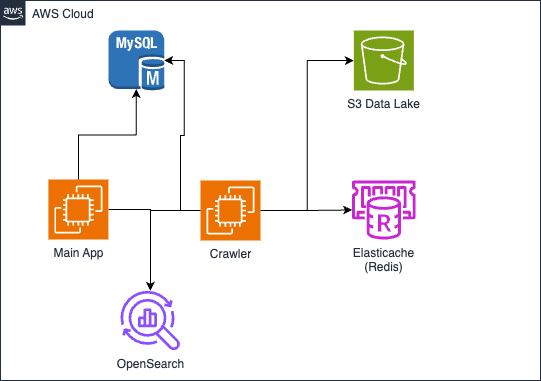
S3 holds a data lake of scrapped data from those FnB websites from a service provider that does the job, what we receive are json files categorized by service. Data is consistently pushed by this service provider on a daily basis and each service might provide more stores than another (based on location and utilization of that service in that location)
The crawler is a javascript application written with all the business logic, it reads the json files from S3 and parses them based on a pre-defined business logic which can create stores when needed and compare the store in the MySql database versus the value from S3 for any changes to be able to trigger a notification that a price of a product changed or new products are added or promotion added by that store or rating of that store increased/decreased.
The crawler saves data in two places: a MySql database hosted on RDS and an OpenSearch instance that helps in fetching records on the main application faster
The Elasticache Redis is used for GraphQL Subscription Pub/Sub to provide details of how much a crawler has completed and queueing of tasks for the crawler to go with (utilizing NestJS's queueing libraries and pub/sub that relies on Redis)
The Main Issue
The issue with the crawler that it was reading each store from S3 and comparing it to an existing record in the database one by one
This includes comparing:
- the store itself
- products related to that store incase it needs to create or update or flag asunavailable
- promotions made by this store in case of creating, updating, and removing
As the number of stores and products increase, time to process would increase and this is due to the fact that Javascript's Event Loop is single threaded hence if you are parsing a file with 50,000 stores and each store has on average 50 products (assumption here because certain stores might have less or more but a rough number) and promotions can be single or multiple in terms of store promotions or specific product promotions, values can be 50,000 to 100,000 promotions per file (assumptions because value can fluctuate per day), you are parsing them under one thread even if you have a large server with multiple threads (the current customer's server is a r5.xlarge which has 4 threads, cost on un-utilized resources)
Hence you have to loop over:
- 50,000 stores
- 250,000 products
- 50,000 - 100,000 promotions
And the products and promotions are nested within the store hence you are doing a double loop on the inside all under one thread along with waiting time for the database to return back data for each store in each iteration of the loop which was spiking the database to 90% utilization when a crawler is running
The smallest crawler would take time ranging between 2-6 hours but certain crawlers with large files might take 1-2 days to finish which might skip on crawling files on other days and when a crawler takes over to run, it blocks other crawlers which delays other crawlers from working
Bottlenecks to deal with
The bottleneck related to this crawler system are the following:
- Javascript's Event Loop being single threaded
- Excessive database calls on each iteration of the loop which is slowing down the database all together
- Event Loop blocking the main thread causing other actions on the server to halt till the crawler's loop finishes

But the most important bottleneck is that the client does not want to rewrite the crawler's code from scratch, he wants the current crawler code to run faster since it contains all the business logic that he wants and does not want to risk recreating a new crawler that might produce different results than what he wants
A basic suggestion would be to containerize the crawler and launch multiple ones at the same time but one crawler is utilizing the database to 90% then certain change needs to be done before deploying multiple containers of the crawler
Proposed solution and implementation
We have experimented with multiple suggestions till we reach to an ideal outcome that suits the client
The first proposed solution was to drop the database consumption to reasonable numbers, what we did before going through the comparison loop that we fetch all stores with products and promotions then do the comparison locally then at the end we bulk insert to the database when comparison ends. This method have decreased the database consumption from 90% to 10% on the heaviest crawler on the system
While the database consumption did drop, the crawler's time to process didn't decrease thus we needed to go towards a different strategy
Chunking the records in batches didn't offer significant change but it would start to make a difference when we started utilizing NodeJS's worker threads module (https://nodejs.org/api/worker_threads.html) but we decided to utilize a library called Piscina (https://github.com/piscinajs/piscina) which removed the abstractions of dealing with worker threads manually
Worker threads help execute different cpu based tasks in multiple parallel contexts concurrently, allowing to provide multi-threading and multi-processing in Javascript. The only trick with utilizing worker threads that you do not have the data from the main thread's context thus you have to manually pass it down to each worker thread you are going to use to perform the requested job
Since we are starting to do all the comparison locally then what we are doing are cpu tasks, chunking the records into batches and sending each batch into a thread decreased our process time significantly
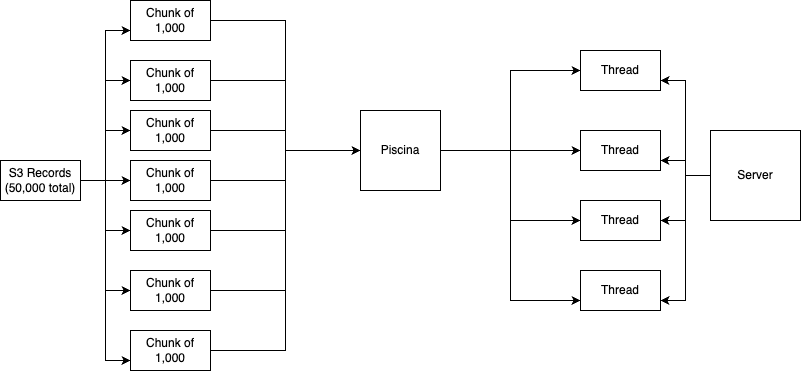
Piscina would handle all the chunks asynchronously and queues the worker thread tasks when needed in which we utilize the threads on the server when available and when it is not available doing any cpu task, it would wait in the queue till a thread becomes available to process
Now we can process more records at the same time, chunking the stores into 500 store batches have helped in speeding the process significantly while undergoing the same process and all the business logic intact
With this solution we are able to process 2,500 stores at the same time doing the comparison rather than looping record by record, utilizing the server to its fullest while doing the same work with the same business logic
Results from the new solution
With the implemented solution, the crawler run time have dropped from 6 hours to 20 minutes as for the biggest crawler that used to take days now takes maximum 2 hours to process the data and insert to the database
This solution provided the benchmarks that the client was asking for while keeping the same business logic intact and in the least amount of time possible to process the data
And something to note here that we kept using the same server type (r5.xlarge which has 4 virtual cpus) but now we are utilizing the server fully
Honorable mentions about serverless
While we could have utilized Lambda with Step Functions to do this task but there are certain things to keep in mind:
- time constraints from the client to deliver this update
- the code contained multiple dependency injections (using NestJS) which makesit difficult to port to Lambda
- client's requirement to see the processing in real-time (which the existing code was doing)
Next Steps
After this update for the crawler, the crawler server became under-utilized in terms that it is processed all the tasks in the day thus it is running in idle for a good sum of the day
Next step is containerizing the crawler's code as a Docker container and launch it when a file on S3 gets pushed. By utilizing SQS, Lambda, ECS, and ECR that we are able to do the same work when needed where when a file on S3 is present then it would add it to the SQS queue which triggers a Lambda function that starts an ECS Fargate task that reads the container image from ECR
Since the application is dealing with large number of records, shifting from MySQL on RDS towards AWS Redshift would be ideal since Redshift excels in data warehousing and managing large sets of data
In the future I will document the process of utilizing ECS with S3 events along with migrating the data from RDS to AWS Redshift
Related work
-
AWS Beirut Community Day 2023
On September 9, the AWS Beirut Community have hosted their first community day with 3 workshops, 6 speakers, and discussion panel. The following schedule went as follows: Talks:…
-
Podcast #18 - Wesley Faulkner: AWS, Community Management, DevRel
Here is my interview with Wesley Faulkner, Senior Community Manager at AWS.
-
Podcast #4 - Faz: Advocating on AWS
This is my interview with Faz, a Senior Developer Advocate at AWS.